
Search
Results
Professional Activities
I have been involved in a number of review and event organization activities.
Meet Knowly, your new AI-based research assistant
Submitted by rene on Sun, 2018-02-04 08:13.
Our first beta version of Knowly.ai is now online. Tired of going through tons of research paper PDFs on your own? Knowly is an AI-based research assistant that can read papers for you and will support you in research-related tasks.
Publications
Goto: Papers | Journal Articles | Authored Books | Book Chapters | Edited Proceedings | Posters & Demos | Technical Reports | Tutorials
For more filtering and export options, you can go to the Semantic Software Lab Publications site.
Selected Talks
Invited Talks and Keynotes
Invited Talk, Semantic Support for Software Requirements Engineering: The ReqWiki Approach, March 13, 2015, Institute for Infocomm Research (I2R), Singapore.
Invited Talk, Bringing Summarization to End Users: Semantic Assistants for Integrating NLP Web Services and Desktop Clients, May 24, 2011, Workshop on Text Summarization (TS11), St. John's, Newfoundland, Canada.
Keynote Talk, Natural Language Processing for the Masses: The Semantic Assistants Project, November 10th, 2010, Atlantic Workshop on Semantics and Services (AWOSS10.2), Moncton, NB, Canada.
Invited Talk, NLP for the Masses: Integrating GATE with Desktop Clients, September 1st, 2010, 3rd GATE Training Course and Developer Sprint (FIG3), Concordia University, Montréal, Québec, Canada.
Invited Talk, Am Anfang war das Mock-up: Zur Genese des DEAFél aus Sicht des Informatikers, July 2nd, 2010, Heidelberger Akademie der Wissenschaften, Germany.
Invited Talk, Software Engineering and Natural Language Processing: Friends or Foes? February 26th, 2010. University of Sheffield, UK.
Invited Talk, Software Engineering and Natural Language Processing: Friends or Foes? July 30th, 2009. Friedrich Schiller University of Jena, Germany.
Invited Talk, Software Engineering and Natural Language Processing: Friends or Foes? February 26th, 2009. Colloques du DIRO, Université de Montréal, Québec, Canada.
Invited Talk, Semantic Software Engineering. January 14th, 2008. Concordia University, Montréal, Québec, Canada.
Invited Talk, Ontology and Text Mining: Connecting your documents with the real world. July 5th, 2007. University of Aberdeen, Scotland, UK.
Invited Speaker, Empowering Software Maintainers with Semantic Web Technologies. June 6th, 2007. 3rd International Workshop on Semantic Web Enabled Software Engineering (SWESE 2007), Innsbruck, Austria.
Invited Talk, Ontology and Text Mining: Connecting your documents with the real world. February 28th, 2007. Institute for Infocomm Research (I2R), Knowledge Discovery Department, Singapore.
Invited Talk, Ontology and Text Mining: Connecting your documents with the real world. February 23rd, 2007. Korea Advanced Institute of Science and Technology (KAIST), Daejeon, South Korea.
Invited Talk, Text Mining. June 28th, 2005. Artificial Intelligence Seminar Series, University of Luxembourg.
Invited Talk, Text Mining. December 9th, 2004. European Media Lab (EML), Villa Bosch, Heidelberg, Germany.
Invited Talk, Representing and Processing Uncertain and Imprecise Information. April 15th, 2002. Concordia University, Montréal, Québec, Canada.
Research
Biography
Dr. René Witte is currently a tenured associate professor within the Department of Computer Science and Software Engineering at Concordia University in Montréal, Canada, where he is heading the Semantic Software Lab. Previously, he worked at Universität Karlsruhe (TH) (now Karlsruhe Institute of Technology, KIT) in Germany within Prof. Dr. Peter C. Lockemann's research group at the Institute for Program Structures and Data Organization (IPD). He also has more than five years of professional work experience in the IT and software industry. Dr. Witte received his Diplom (the German equivalent of a M.Sc.) in Informatics (Computer Science) in 1996 and his "Dr.-Ing." (Doctor of Engineering) in 2002, both from the Faculty of Informatics at Universität Karlsruhe. During the last 10 years, he co-authored more than 70 publications and received four best paper&poster awards. His research has been funded by major funding agencies and industry, including NSERC, MITACS, and the DRDC, and spans both national and international cooperations. He has also given invited talks and conference keynote speeches on multiple occasions and is a frequent reviewer for international conferences, workshops, and projects.
Towards a Systematic Evaluation of Protein Mutation Extraction Systems
Abstract
The development of text analysis systems targeting the extraction of information about mutations from research publications is an emergent topic in biomedical research. Current systems differ in both scope and approaches, which prevents a meaningful comparison of their performance and therefore possible synergies. To overcome this "evaluation bottleneck," we developed a comprehensive framework for the systematic analysis of mutation extraction systems, precisely defining tasks and corresponding evaluation metrics that will allow a comparison of existing and future applications.
Keywords: mutation extraction systems; mutation evaluation tasks; mutation evaluation metrics
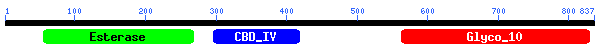
Mutation Miner (CPI 2005)
Introduction
Biological researchers today have access to vast amounts of exponentially growing research data in a structured form within several publicly accessible databases. A large proportion of salient information is however still hidden within individual research papers, since costly manual database curation efforts are overwhelmed by the scale of new information being generated. In the domain of protein engineering, critical units of information required from the literature include: the identity of the mutated protein, the identity and position of wild type residues that are mutated, the identity of the resulting mutant residues and the impacts of the mutations on functional properties of the proteins.
Mutation Miner is a system designed to automate the extraction of mutations and textual annotations describing the impacts of mutations on protein properties (mutation annotations) from full text scientific literature. Furthermore, the system retrieves and carries out bioinformatic analyses on mutated sequences providing the mapped coordinates of mutants on a selected structure. Integration of multiple formatted mutation annotations with associated residue coordinates facilitates their rendering with structure visualization tools. We describe the architecture and tools that support Mutation Miner (Text mining-NLP, Sequence Analysis, Structure Visualization) and present performance evaluations that demonstrate the feasibility of this approach.
Enhanced Semantic Access to the Protein Engineering Literature using Ontologies Populated by Text Mining
Abstract
The biomedical literature is growing at an ever-increasing rate, which pronounces the need to support scientists with advanced, automated means of accessing knowledge. We investigate a novel approach employing description logics (DL)-based queries made to formal ontologies that have been created using the results of text mining full-text research papers. In this paradigm, an OWL-DL ontology becomes populated with instances detected through natural language processing (NLP). The generated ontology can be queried by biologists using DL reasoners or integrated into bioinformatics workflows for further automated analyses. We demonstrate the feasibility of this approach with a system targeting the protein mutation literature.
Keywords: text mining; semantic web; ontological NLP; protein mutations; automated reasoning in bioinformatics; querying OWL-DL ontologies; description logics.
Mutation Miner (ISMB 2005)
Introduction
Biological researchers today have access to vast amounts of exponentially growing research data in a structured form within several publicly accessible databases. A large proportion of salient information is however still hidden within individual research papers, since costly manual database curation efforts are overwhelmed by the scale of new information being generated. In the domain of protein engineering, critical units of information required from the literature include: the identity of the mutated protein, the identity and position of wild type residues that are mutated, the identity of the resulting mutant residues and the impacts of the mutations on functional properties of the proteins.
Mutation Miner is a system designed to automate the extraction of mutations and textual annotations describing the impacts of mutations on protein properties (mutation annotations) from full text scientific literature. Furthermore, the system retrieves and carries out bioinformatic analyses on mutated sequences providing the mapped coordinates of mutants on a selected structure. Integration of multiple formatted mutation annotations with associated residue coordinates facilitates their rendering with structure visualization tools. We describe the architecture and tools that support Mutation Miner (Text mining-NLP, Sequence Analysis, Structure Visualization) and present performance evaluations that demonstrate the feasibility of this approach.