
Search
Results
Flexible Ontology Population from Text: The OwlExporter
Abstract
 Ontology population from text is becoming increasingly important for NLP applications. Ontologies in OWL format provide for a standardized means of modeling, querying, and reasoning over large knowledge bases. Populated from natural language texts, they offer significant advantages over traditional export formats, such as plain XML. The development of text analysis systems has been greatly facilitated by modern NLP frameworks, such as the General Architecture for Text Engineering (GATE). However, ontology population is not currently supported by a standard component. We developed a GATE resource called the OwlExporter that allows to easily map existing NLP analysis pipelines to OWL ontologies, thereby allowing language engineers to create ontology population systems without requiring extensive knowledge of ontology APIs. A particular feature of our approach is the concurrent population and linking of a domain- and NLP-ontology, including NLP-specific features such as safe reasoning over coreference chains.
Ontology population from text is becoming increasingly important for NLP applications. Ontologies in OWL format provide for a standardized means of modeling, querying, and reasoning over large knowledge bases. Populated from natural language texts, they offer significant advantages over traditional export formats, such as plain XML. The development of text analysis systems has been greatly facilitated by modern NLP frameworks, such as the General Architecture for Text Engineering (GATE). However, ontology population is not currently supported by a standard component. We developed a GATE resource called the OwlExporter that allows to easily map existing NLP analysis pipelines to OWL ontologies, thereby allowing language engineers to create ontology population systems without requiring extensive knowledge of ontology APIs. A particular feature of our approach is the concurrent population and linking of a domain- and NLP-ontology, including NLP-specific features such as safe reasoning over coreference chains.
Generating an NLP Corpus from Java Source Code: The SSL Javadoc Doclet
Abstract
 Source code contains a large amount of natural language text, particularly in the form of comments, which makes it an emerging target of text analysis techniques. Due to the mix with program code, it is difficult to process source code comments directly within NLP frameworks such as GATE. Within this work we present an effective means for generating a corpus using information found in source code and in-line documentation, by developing a custom doclet for the Javadoc tool. The generated corpus uses a schema that is easily processed by NLP applications, which allows language engineers to focus their efforts on text analysis tasks, like automatic quality control of source code comments. The SSLDoclet is available as open source software.
Source code contains a large amount of natural language text, particularly in the form of comments, which makes it an emerging target of text analysis techniques. Due to the mix with program code, it is difficult to process source code comments directly within NLP frameworks such as GATE. Within this work we present an effective means for generating a corpus using information found in source code and in-line documentation, by developing a custom doclet for the Javadoc tool. The generated corpus uses a schema that is easily processed by NLP applications, which allows language engineers to focus their efforts on text analysis tasks, like automatic quality control of source code comments. The SSLDoclet is available as open source software.
A Belief Revision Approach to Textual Entailment Recognition
Abstract
An artificial believer has to recognize textual entailment to categorize beliefs. We describe our system – the Fuzzy Believer system – and its application to the TAC/RTE three-way task.
Semantic Technologies in System Maintenance (STSM 2008)

Abstract
This paper gives a brief overview of the International Workshop on Semantic Technologies in System Maintenance. It describes a number of semantic technologies (e.g., ontologies, text mining, and knowledge integration techniques) and identifies diverse tasks in software maintenance where the use of semantic technologies can be beneficial, such as traceability, system comprehension, software artifact analysis, and information integration.
Empowering Software Maintainers with Semantic Web Technologies

Abstract
Software maintainers routinely have to deal with a multitude of artifacts, like source code or documents, which often end up disconnected, due to their different representations and the size and complexity of legacy systems. One of the main challenges in software maintenance is to establish and maintain the semantic connections among all the different artifacts. In this paper, we show how Semantic Web technologies can deliver a unified representation to explore, query and reason about a multitude of software artifacts. A novel feature is the automatic integration of two important types of software maintenance artifacts, source code and documents, by populating their corresponding sub-ontologies through code analysis and text mining. We demonstrate how the resulting "Software Semantic Web" can support typical maintenance tasks through ontology queries and DL reasoning, such as security analysis, architectural evolution, and traceability recovery between code and documents.
Keywords: Software Maintenance, Ontology Population, Text Mining.
Automatic Traceability Recovery: An Ontological Approach
Abstract
Software maintainers routinely have to deal with a multitude of artifacts, like source code or documents. These artifacts often end up disconnected from each other, due to their different representations and levels of abstractions. One of the main challenges in software maintenance therefore is to recover and maintain the semantic connections among these artifacts. In this research, we present a novel approach that addresses this traceability issue by creating formal ontological representations for both software documentation and source code artifacts. The resulting representations are then aligned to establish traceability links at semantic level. Ontological queries and reasoning can be applied on these representations to infer and establish additional traceability links to support specific maintenance tasks.
Categories and Subject Descriptors: D2.7 [Distribution, Maintenance, and Enhancement]: Documentation, Restructuring, reverse engineering
General Terms: Software, Documentation, Management
Keywords: Ontologies, Traceability, Software Maintenance
Ontology-based Program Comprehension Tool Supporting Website Architectural Evolution
Abstract
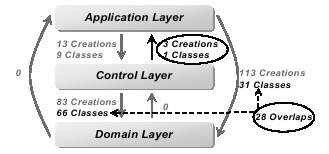 A challenge of existing program comprehension approaches is to provide consistent and flexible representations for software systems. Maintainers have to match their mental models with the different representations these tools provide. In this paper, we present a novel approach that addresses this issue by providing a consistent ontological representation for both source code and documentation. The ontological representation unifies information from various sources, and therefore reduces the maintainers’ comprehension efforts. In addition, representing software artifacts in a formal ontology enables maintainers to formulate hypotheses about various properties of software systems. These hypotheses can be validated through an iterative exploration of information derived by our ontology inference engine. The implementation of our approach is presented in detail, and a case study is provided to demonstrate the applicability of our approach during the architectural evolution of a website content management system.
A challenge of existing program comprehension approaches is to provide consistent and flexible representations for software systems. Maintainers have to match their mental models with the different representations these tools provide. In this paper, we present a novel approach that addresses this issue by providing a consistent ontological representation for both source code and documentation. The ontological representation unifies information from various sources, and therefore reduces the maintainers’ comprehension efforts. In addition, representing software artifacts in a formal ontology enables maintainers to formulate hypotheses about various properties of software systems. These hypotheses can be validated through an iterative exploration of information derived by our ontology inference engine. The implementation of our approach is presented in detail, and a case study is provided to demonstrate the applicability of our approach during the architectural evolution of a website content management system.
Keywords: Program Comprehension, Software Evolution, Ontology, Automated Reasoning
Fuzzy Extensions for Reverse Engineering Repository Models
Abstract
 Reverse Engineering is a process fraught with imperfections. The importance of dealing with non-precise, possibly inconsistent data explicitly when interacting with the reverse engineer has been pointed out before.
Reverse Engineering is a process fraught with imperfections. The importance of dealing with non-precise, possibly inconsistent data explicitly when interacting with the reverse engineer has been pointed out before.
In this paper, we go one step further: we argue that the complete reverse engineering process must be augmented with a formal representation model capable of modeling imperfections. This includes automatic as well as human-centered tools.
We show how this can be achieved by merging a fuzzy set-theory based knowledge representation model with a reverse engineering repository. Our approach is not only capable of modeling a wide range of different kinds of imperfections (uncertain as well as vague information), but also admits robust processing models by defining explicit degrees of certainty and their modification through fuzzy belief revision operators.
The repository-centered approch is proposed as the foundation for a new generation of reverse engineering tools. We show how various RE tasks can benefit from our approach and state first design ideas for fuzzy reverse engineering tools.
Text Mining and Software Engineering: An Integrated Source Code and Document Analysis Approach
Abstract
Documents written in natural languages constitute a major part of the artifacts produced during the software engineering lifecycle. Especially during software maintenance or reverse engineering, semantic information conveyed in these documents can provide important knowledge for the software engineer. In this paper, we present a text mining system capable of populating a software ontology with information detected in documents. A particular novelty is the integration of results from automated source code analysis into an NLP pipeline, allowing to cross-link software artifacts represented in code and natural language on a semantic level.
Traceability in Software Engineering - Past, Present and Future
CASCON 2007 Workshop Report
IBM Technical Report: TR-74-211
October 25, 2007
Abstract
Many changes have occurred in software engineering research and practice since 1968, when software engineering as a research domain was established. One of these research areas is traceability, a key aspect of any engineering discipline, enables engineers to understand the relations and dependencies among various artifacts in a system.