
Search
Results
SE-Advisor
The SE-ADVISOR tool presents a novel approach to support software evolution, by integrating maintenance relevant knowledge resources, processes, and their constituents. We demonstrate how our SE-ADVISOR environment can provide contextual guidance during typical maintenance tasks through the use of ontological queries and reasoning services.
Story-driven Approach to Software Evolution

Abstract
From a maintenance perspective, only software that is well understood can evolve in a controlled and high-quality manner. Software evolution itself is a knowledge-driven process that requires the use and integration of different knowledge resources. The authors present a formal representation of an existing process model to support the evolution of software systems by representing knowledge resources and the process model using a common representation based on ontologies and description logics. This formal representation supports the use of reasoning services across different knowledge resources, allowing for the inference of explicit and implicit relations among them. Furthermore, an interactive story metaphor is introduced to guide maintainers during their software evolution activities and to model the interactions between the users, knowledge resources and process model.
Ontological Approach for the Semantic Recovery of Traceability Links between Software Artifacts

Abstract
Traceability links provide support for software engineers in understanding relations and dependencies among software artefacts created during the software development process. The authors focus on re-establishing traceability links between existing source code and documentation to support software maintenance. They present a novel approach that addresses this issue by creating formal ontological representations for both documentation and source code artefacts. Their approach recovers traceability links at the semantic level, utilising structural and semantic information found in various software artefacts. These linked ontologies are supported by ontology reasoners to allow the inference of implicit relations among these software artefacts.
A Self-Learning Context-Aware Lemmatizer for German

Abstract
Accurate lemmatization of German nouns mandates the use of a lexicon. Comprehensive lexicons, however, are expensive to build and maintain. We present a self-learning lemmatizer capable of automatically creating a full-form lexicon by processing German documents.
Converting a Historical Architecture Encyclopedia into a Semantic Knowledge Base
Abstract
 Digitizing a historical document using ontologies and natural language processing techniques can transform it from arcane text to a useful knowledge base.
Digitizing a historical document using ontologies and natural language processing techniques can transform it from arcane text to a useful knowledge base.
Beyond Information Silos — An Omnipresent Approach to Software Evolution
Abstract
 Nowadays, software development and maintenance are highly distributed processes that involve a multitude of supporting tools and resources. Knowledge relevant for a particular software maintenance task is typically dispersed over a wide range of artifacts in different representational formats and at different abstraction levels, resulting in isolated 'information silos'. An increasing number of task-specific software tools aim to support developers, but this often results in additional challenges, as not every project member can be familiar with every tool and its applicability for a given problem. Furthermore, historical knowledge about successfully performed modifications is lost, since only the result is recorded in versioning systems, but not how a developer arrived at the solution. In this research, we introduce conceptual models for the software domain that go beyond existing program and tool models, by including maintenance processes and their constituents. The models are supported by a pro-active, ambient, knowledge-based environment that integrates users, tasks, tools, and resources, as well as processes and history-specific information. Given this ambient environment, we demonstrate how maintainers can be supported with contextual guidance during typical maintenance tasks through the use of ontology queries and reasoning services.
Nowadays, software development and maintenance are highly distributed processes that involve a multitude of supporting tools and resources. Knowledge relevant for a particular software maintenance task is typically dispersed over a wide range of artifacts in different representational formats and at different abstraction levels, resulting in isolated 'information silos'. An increasing number of task-specific software tools aim to support developers, but this often results in additional challenges, as not every project member can be familiar with every tool and its applicability for a given problem. Furthermore, historical knowledge about successfully performed modifications is lost, since only the result is recorded in versioning systems, but not how a developer arrived at the solution. In this research, we introduce conceptual models for the software domain that go beyond existing program and tool models, by including maintenance processes and their constituents. The models are supported by a pro-active, ambient, knowledge-based environment that integrates users, tasks, tools, and resources, as well as processes and history-specific information. Given this ambient environment, we demonstrate how maintainers can be supported with contextual guidance during typical maintenance tasks through the use of ontology queries and reasoning services.
Proceedings of the Workshop New Challenges for NLP Frameworks (NLPFrameworks 2010)
Background
 Natural language processing frameworks like GATE and UIMA have significantly changed the way NLP applications are designed, developed, and deployed. Features such as component-based design, test-driven development, and resource meta-descriptions now routinely provide higher robustness, better reusability, faster deployment, and improved scalability. They have become the staple of both NLP research and industrial application, fostering a new generation of NLP users and developers.
Natural language processing frameworks like GATE and UIMA have significantly changed the way NLP applications are designed, developed, and deployed. Features such as component-based design, test-driven development, and resource meta-descriptions now routinely provide higher robustness, better reusability, faster deployment, and improved scalability. They have become the staple of both NLP research and industrial application, fostering a new generation of NLP users and developers.
These are the proceedings of the workshop New Challenges for NLP Frameworks (NLPFrameworks 2010), held in conjunction with LREC 2010, which brought together users and developers of major NLP frameworks.
Minding the Source: Automatic Tagging of Reported Speech in Newspaper Articles

Abstract
Reported speech in the form of direct and indirect reported speech is an important indicator of evidentiality in traditional newspaper texts, but also increasingly in the new media that rely heavily on citation and quotation of previous postings, as for instance in blogs or newsgroups. This paper details the basic processing steps for reported speech analysis and reports on performance of an implementation in form of a GATE resource.
Predicate-Argument EXtractor (PAX)
Abstract
 Screenshot of MultiPAX resultsIn this paper, we describe the open source GATE component PAX for extracting predicate-argument structures (PASs). PASs are used in various contexts to represent relations within a sentence structure. Different ``semantic'' parsers extract relational information from sentences but there exists no common format to store this information. Our predicate-argument extractor component (PAX) takes the annotations generated by selected parsers and transforms the parsers' results to predicate-argument structures represented as triples (subject-verb-object). This allows downstream components in an analysis pipeline to process PAS triples independent of the deployed parser, as well as combine the results from several parsers within a single pipeline.
Screenshot of MultiPAX resultsIn this paper, we describe the open source GATE component PAX for extracting predicate-argument structures (PASs). PASs are used in various contexts to represent relations within a sentence structure. Different ``semantic'' parsers extract relational information from sentences but there exists no common format to store this information. Our predicate-argument extractor component (PAX) takes the annotations generated by selected parsers and transforms the parsers' results to predicate-argument structures represented as triples (subject-verb-object). This allows downstream components in an analysis pipeline to process PAS triples independent of the deployed parser, as well as combine the results from several parsers within a single pipeline.
Semantic Content Access using Domain-Independent NLP Ontologies
Abstract
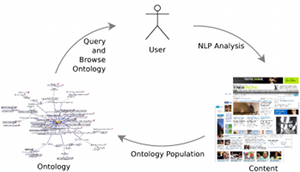 We present a lightweight, user-centred approach for document navigation and analysis that is based on an ontology of text mining results. This allows us to bring the result of existing text mining pipelines directly to end users. Our approach is domain-independent and relies on existing NLP analysis tasks such as automatic multi-document summarization, clustering, question-answering, and opinion mining. Users can interactively trigger semantic processing services for tasks such as analyzing product reviews, daily news, or other document sets.
We present a lightweight, user-centred approach for document navigation and analysis that is based on an ontology of text mining results. This allows us to bring the result of existing text mining pipelines directly to end users. Our approach is domain-independent and relies on existing NLP analysis tasks such as automatic multi-document summarization, clustering, question-answering, and opinion mining. Users can interactively trigger semantic processing services for tasks such as analyzing product reviews, daily news, or other document sets.